CNN 是一个简单的网络结构,初学者一般从MNIST入手,提及CNN第一印象可能只有经典的图像分类的那个model。深入了解才会发现,学术圈和工业界是如何通过稍稍改变 Feature Map 之后的结构和目标函数等实现各种复杂任务,这其中迸发的想象力让人激动。
“Image Feature Learning for Cold Start Problem in Display Advertising“ 这篇文章发表在ijcai15,是腾讯把图像特征应用到广告ctr预估的总结,同时也解答了广告中什么区域对点击率影响较大。这篇文章是较早把图像的深度特征用于点击率预估的工作之一,2015年的时候,推荐学术界里在深度学习方面起到重要影响的文章 Wide and Deep 、Youtube Rec with DNN 和一些 RNN 做推荐的方法尚未出现,高维稀疏特征的one hot encode embedding 成低维稠密特征的方法尚未被大众熟悉,所以这篇文章的做法并不是直接端到端的结构,而是通过CNN 抽取图像特征,然后用到 Logistic Regression(LR) 等常见的CTR模型中使用。
下面进入广告时间,猜猜什么因素导致左边点击率高,文末有答案。

文章主要想法分为两步,第一步,利用卷积神经网络,实现从原始像素到用户点击反馈的 end-to-end 的图像特征学习。第二步,训练好的CNN可以抽取与点击率相关的图像特征,外加广告属性的特征,这些特征综合起来训练LR等模型来预估最终点击率。
抽取图像特征的网络结构如下:
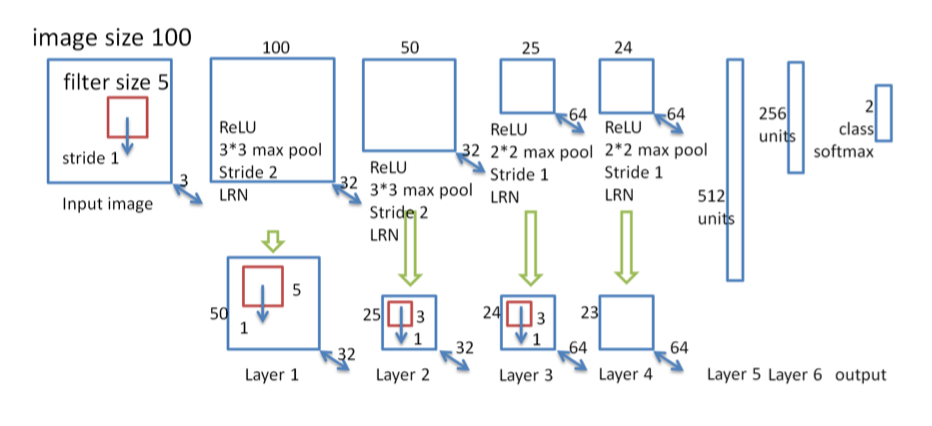
100*100像素图像输入 => 4层conv+pool => 3层FC => 二分类softmax(点击率)
视觉元素的位置重要性
传统的图像分类只关心是否包含某个视觉元素,而不关心该视觉元素在图像中的位置。对于展示面积比较大的广告图片,因为用户的视觉焦点一般在图像中心,关键的视觉元素在图像中的位置对于点击率有明显影响,因此设计的卷积神经网络的最后一层卷积输出层的feature map应该稍大,以传递原图的位置信息。
数据集
-
样本规模:470亿样本,样本来源于腾讯在线广告日志,包含5种类别,5 种展示位置。样本数据量太大,直接用CNN训练在时间上不可接受,因此作者吧相同的图片聚合一起,形成二维样本<未点击数,点击数>。文章没有提到的一点是,<1000,10> 和 <100, 1> 从统计上来说点击率相同,训练的时候有什么区别?我猜测对梯度应该有一定影响,样本数量越大,步长越长。
-
数据增强:25万张广告图片,划分为22万张训练集和3.3万张测试集。训练集缩放裁剪到 128 * 128像素大小,然后随机裁剪 100 * 100 子图作为卷积网络的输入。测试集随机裁剪 10 次,用输出概率的平均值作为最后的预测结果。
-
单机GPU训练 2 天
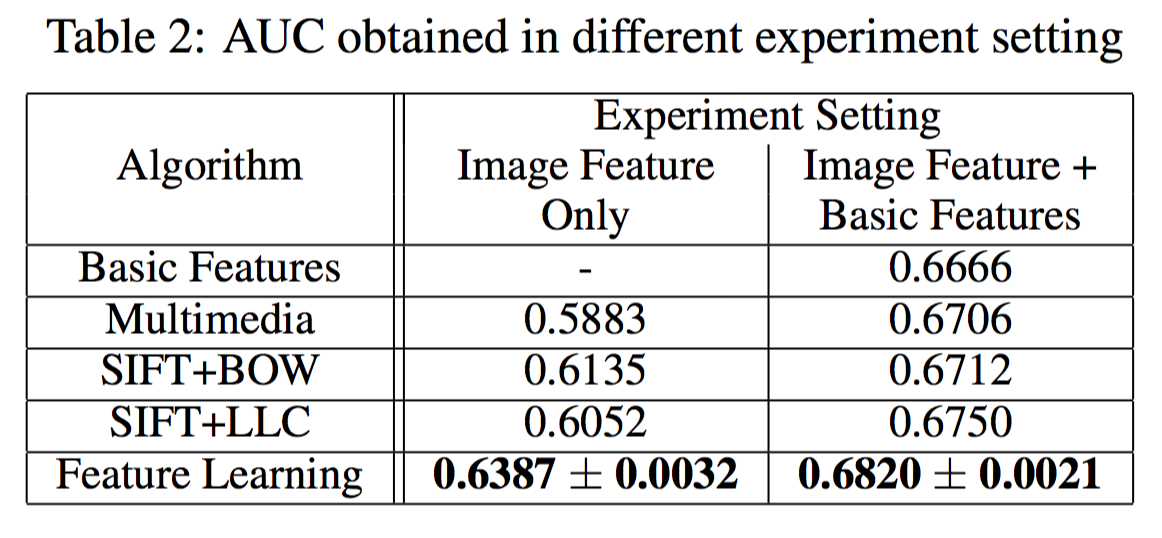
实验结果
做了两种版本的比较,第一种只用图像特征,第二种包括广告id、类目id和展示位置id三个额外特征,分别用LR模型预测ctr,用AUC离线评测:
什么影响点击率
用可视化方法,可以观察d奥图片模特人脸区域和文字区域对点击率影响比较大:

附:公众号
